He is back !
Et non, ce blog n’est pas mort ! Mais oui je dois avouer que le contexte actuel qui chamboule nos vies ne laisse pas beaucoup de temps aux tests/bidouillages et encore moins à la rédaction de billets de blogs…

Du coup, l’idée va être de faire différemment, plutôt que de ne pas faire du tout 🙂 On pourrait presque parler de méthode Agile en fait. Plutôt que de ne rien livrer du tout, je vais faire un post en mode « work in progress ». En fonction du moment où vous lirez ce texte, il sera plus ou moins complet et/ou modifié. Mais :
- Ça peut toujours à servir à quelqu’un, même en l’état
- C’est pour moi une forme de bloc-notes qui me permettra de me rappeler de mon état d’avancement
- Si jamais un « sachant » (3 points au bingo réunion suivi de projet) passe par ici et veut me filer un coup de main en commentaires, je suis preneur
Bref, après tout ce blabla, attaquons donc l’intégration d’ORS au « stack » Elastic
On attaque avec un gros mot : « ELK »
Qu’est-ce que signifie donc « ELK » :
- Elasticsearch
- LogStash
- Kibana
Il s’agit des 3 principaux composants nécessaires dans une majorité des cas quand on monte une suite Elasticsearch. Ah oui j’ai oublié de préciser : je ne suis pas un expert concernant Elastic. Pour tout dire, je découvre même Elastic avec ce side project. Donc j’espère que vous saurez être magnanime 😉
Elasticsearch est la base même de cette suite. Il s’agit d’un ensemble base de données + moteur de requêtes + API permettant d’y accéder. En comparaison avec d’autres bases de données, il a comme caractéristiques d’être facilement scalable en ajoutant des noeuds en fonction de vos besoins de redondance et/ou de performance, et de permettre de stocker des données non déterminées à l’avance. Oubliez les types précis associés aux colonnes des moteurs SQL habituels. Ici du moment que vous envoyez du JSON, il saura quoi en faire 🙂
LogStash est en approximation un ETL. Vous allez lui fournir des fichiers de logs et le mapping qui va bien, et il va en extraire les données qui vous intéresse, avant de les envoyer à Elasticsearch. Cette explication est plus « pour information » car dans le cas qui nous intéresse, ORS va se charger lui-même d’envoyer les données en base de données. Mais bon, on sait jamais… 🙂
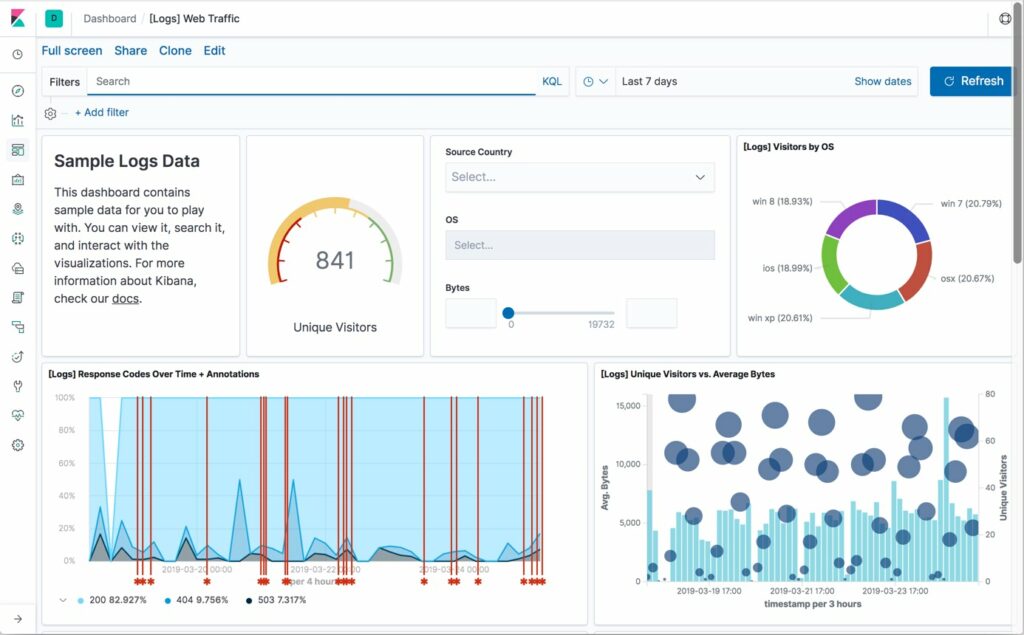
Kibana enfin va vous permettre d’effectuer des requêtes en KQL sur la base de données, et de créer de jolies visualisations de toutes ces données, afin de les expliciter
Hop, on commence l’installation
Bon contrairement à d’habitude, je ne vais pas vous faire les installations d’Elasticsearch et Kibana pas à pas car elles sont relativement simples, pas loin du « Next – Next – Next » que l’on aurait sous Windows. La page qui va bien : https://www.elastic.co/guide/en/elastic-stack/current/installing-elastic-stack.html
Quelques conseils cependant en passant :
- Vous avez peut-être entendu parler de fuites de données récentes où les pirates se sont simplement servis sur des Elasticsearch exposés sur Internet et avec les logins/mots de passe par défaut. Et bien vous savez quoi, ça me surprend pas … J’ai trouvé que la partie modification des mots de passe par défaut était pas forcément explicité. Du coup, pour sécuriser un peu le bazar : https://www.elastic.co/guide/en/elasticsearch/reference/7.11/setup-passwords.html A faire idéalement dès que vous aurez fini l’installation d’Elasticsearch, cela vous évitera d’avoir à reprendre vos fichiers de configuration après coup
- Les options que j’ai modifié dans les fichiers de configuration d’Elasticsearch et Kibana. Pas exhaustif mais une base de départ. Et pour rappel, ce sont des fichiers au format yaml donc l’oeuvre du démon où le moindre espace d’indentation en trop invalidera l’ensemble du fichier. Donc faites très attention à vos modifications, et backup des fichiers d’origine avant de faire quoi que ce soit
- elasticsearch.yml :
- cluster.name: my-cluster-test
- node.name: ES-RHEL8-1
- network.host: AdresseIPdeMonServeur
- http.port: 9200
- discovery.seed_hosts: [« 127.0.0.1 », « [::1] », »AdresseIPdeMonServeur« ]
- cluster.initial_master_nodes: [« ES-RHEL8-1 »]
- kibana.yml :
- server.host: « AdresseIPdeMonServeur«
- server.name: « RHEL8-1 »
- elasticsearch.hosts: [« http://AdresseIPdeMonServeur:9200″]
- elasticsearch.yml :
- Enfin pour valider le bon fonctionnement d’ELK (EK même techniquement) avant de s’attaquer au paramétrage d’ORS, je vous conseille d’installer une des sources de données proposées par défaut dans Kibana dans l’onglet « Add data ». Me concernant j’ai installé MetricBeat qui permet de suivre l’activité de ses serveurs et s’installe très simplement
Et si on faisait quelque chose d’utile maintenant ?
Maintenant que notre suite Elastic est installé, on va pouvoir paramétrer ORS pour qu’il s’interface avec celle-ci. Mais pourquoi faire déjà ? De base, ORS propose 3 fonctions de suivi de son activité qui peuvent ensuite être reportés dans Elastic :
- Session reporting : ORS va stocker des informations sur chaque session créée. Le numéro appelant, la stratégie utilisée, heure de début et de fin,… Apparemment, on peut customiser ces informations en modifiant sa stratégie Composer 🙂
- Performance reporting : ORS dispose d’une fonction de suivi de ses « constantes vitales », qu’il peut de base afficher dans les logs, et créer des alarmes Genesys associées en fonction de seuils. L’intégration à Elasticsearch permet de les monitorer pour suivre l’état de santé de ses nœuds ORS.
- Node reporting : Ici ORS fournira des informations sur les différents nœuds actifs, ainsi que le host sur lequel ils tournent, ainsi que ses ports d’écoute TCP principaux
Activer ces 3 fonctionnalités se fait au niveau du paramétrage d’ORS (ou de la transaction list qui contient ses paramètres, cf. mon article sur l’installation d’ORS) dans la section elasticsearch
- ors-es-session-report = true
- ors-es-perfsnapshot-report = true
- ors-es-node-info-report = true
- ors-es-nodes = http://AdresseIPdeMonServeur:9200
- username = elastic
- password = changeme
Les 3 premières options permettent d’activer les 3 fonctions de suivi présentées précédemment, et les 3 suivantes de vous connecter à votre Elasticsearch. Le username et le password présentés sont ceux par défaut, avant modification
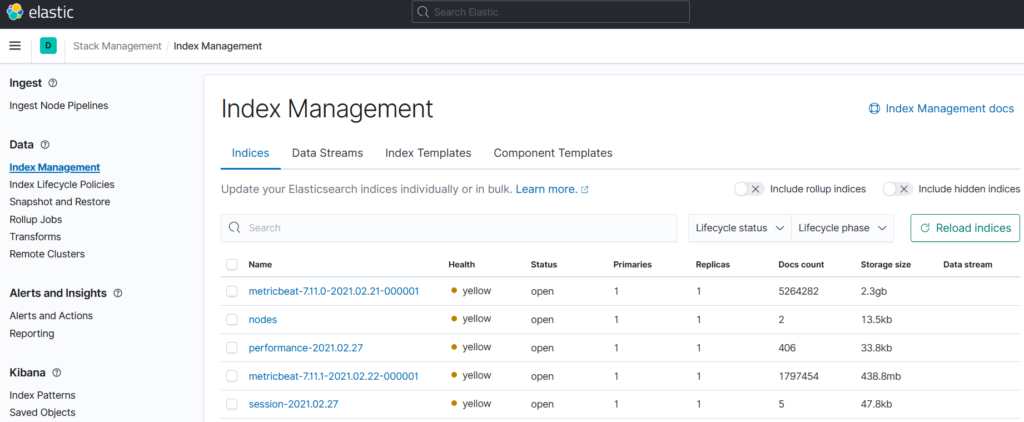
Une fois ces options paramétrées, redémarrez votre ORS et vous devriez voir des données remonter dans Kibana. Pour cela, connectez-vous à celui-ci et allez dans Stack Management > Index Management et vous trouverez de nouveaux « Indices » (l’équivalent d’une base de données dans Elasticsearch) nommés nodes, performance-YYYY.MM.DD et session-YYYY.MM.DD, chacun correspondant encore une fois aux 3 fonctions de reporting proposées.
Ingestion des données
Récapitulons : on a un Elasticsearch fonctionnel, un ORS configuré et des données qui remonte dans Elasticsearch. Maintenant, il pourrait être pratique d’effectuer des requêtes sur celles-ci.
Pour cela, nous allons rester sur la page « Stack Management » mais aller désormais dans Kibana\Index Patterns, puis « Create index pattern »
Sur la seconde page, on va indiquer les index que l’on souhaite « regrouper ». En effet par exemple, les index de session vont être suffixés par la date du jour. Mais bien sûr, on veut pouvoir consolider les données de plusieurs périodes sur un seul graphique. C’est pourquoi par exemple pour consolider les informations de sessions, on va indiquer dans Index pattern name « session-*
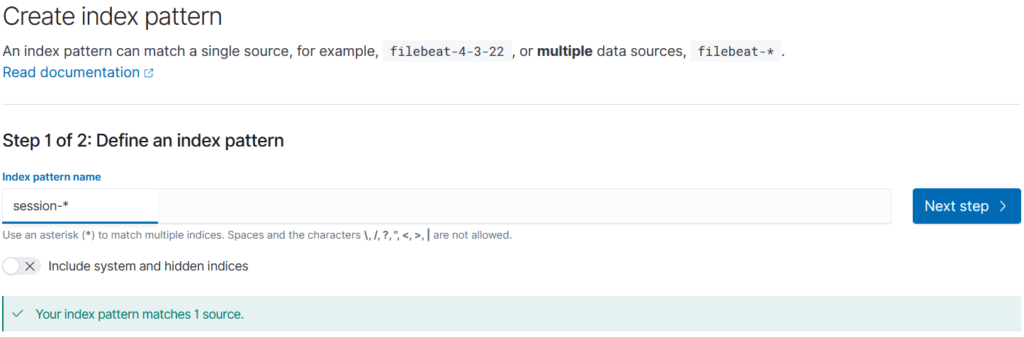
L’étape suivante va consister à indiquer s’il s’agit de données basées sur des informations de date, et auquel cas quelle donnée nous servira « d’abscisse ». Dans le cas des informations de session, on peut ainsi par exemple sélectionner la date de début de session, ou celle de fin :
Maintenant que l’index pattern est créé, on va pouvoir requêter les données présentes dans Elastic grâce à la page Analytics > Discover puis en sélectionnant l’index pattern qui nous intéresse
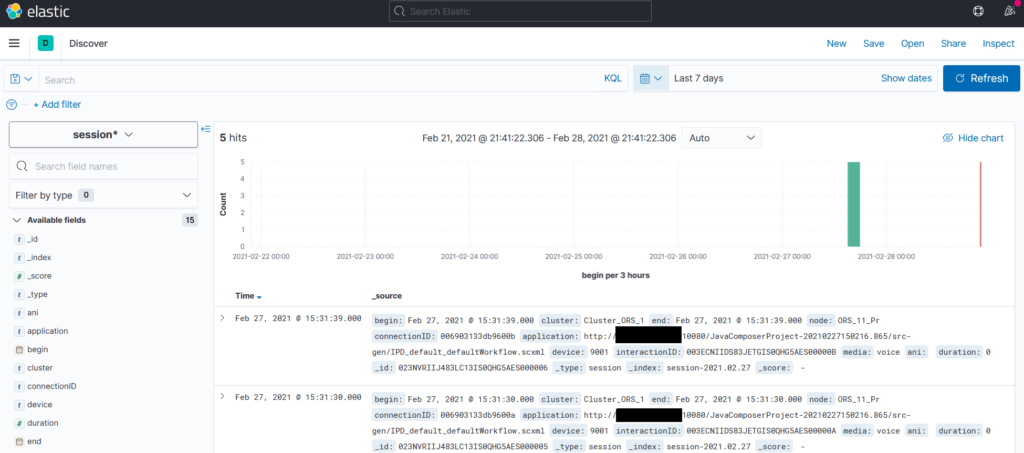
Visualisation des données
Voilà, comme annoncé au début de cet article, ce n’est pas encore fini. Il me reste maintenant à faire de beaux graphiques avec tout cela…
Stay tuned !
c’est bô.
Merci maître Cédric
Bonjour,
Tout d’abord, merci pour tout ce travail accompli sur votre blog. Il m’a bien aidé dans ma démarche d’implantation de l’ORS sur ma plate-forme Génésys. Je comprends mieux le brin d’humour en début de blog avec le fusil. (La mise en place de L’Ors, c’est le supplice de Tantale…)
Malheureusement, Je bute sur un problème depuis 1 semaine. Après avoir suivi point par point et religieusement votre blog, les informations collectées par mon ORS et remontées dans Elasticsearch ne comportent pas d’information sur le Media, l’Ani, l’Application ou l’ID.
Help me. Auriez-vous une idée pour sauver un petit gars en détresse. Merci.
Bonne Journée.
Bonjour ElasOrs,
Désolé pour le délai de réponse, ça m’apprendra à pas surveiller plus attentivement les commentaires du site.
Votre problème s’est-il réglé depuis ? Si non, voyez-vous des infos autres remonter ?
Hello Grutt c’est Afid
Bon bah j’ai pas avancé sur l’ORS et l’elasticsearch, je m’explique
Les champs poussés sur l’elasticsearch depuis l’ors ne sont pas administrables, on as bien deux index de créés cependant ça manque d’information concernant les interactions, ANI, DNIS, UD….
Il est possible via la stratégie de routage Composer d’ajouter un bloc de type HTTP Rest, le configurer :
HTTP Authentification: USER_ELASTIC + PASSWD
URI: url elasticsearch suivi du non de l’index que tu souhaite créer (de préférence variabilisé avec une date)
request method: POST
Input: les donée que tu souhaite stocker sur elk
Après cela il ne te reste plus qu’a aller voir sous kibana ton index…
Avantage: tu peux installer une version récente de elk.
N’hesite pas si tu veux plus d’information ou completer ton tuto, moi je n’ai plus de site benayad.fr ;-(
Merci pour le retour Afid !
Plus beaucoup de temps pour le site, hormis pour les mises à jour « système » 😉
De notre côté, on est aussi passé par les API ElasticSearch pour stocker des données, avec un bon vieux bloc WebRequest dans Composer. Un peu bourrin, mais efficace en effet 🙂