Un billet hyper rapide pour une astuce toute simple.
Si vous avez besoin d’exporter une VM présente sur un ESXi, par exemple pour la réimporter ensuite dans un VMWare Workstation, il vous suffit de télécharger depuis le site de VMWare l’outil « OVFTool ».
Une fois celui-ci installé, il vous suffira de lancer en ligne de commande :
Et non, ce blog n’est pas mort ! Mais oui je dois avouer que le contexte actuel qui chamboule nos vies ne laisse pas beaucoup de temps aux tests/bidouillages et encore moins à la rédaction de billets de blogs…
Non, vraiment, 2020 ne nous aura rien amené de bon…
Du coup, l’idée va être de faire différemment, plutôt que de ne pas faire du tout 🙂 On pourrait presque parler de méthode Agile en fait. Plutôt que de ne rien livrer du tout, je vais faire un post en mode « work in progress ». En fonction du moment où vous lirez ce texte, il sera plus ou moins complet et/ou modifié. Mais :
Ça peut toujours à servir à quelqu’un, même en l’état
C’est pour moi une forme de bloc-notes qui me permettra de me rappeler de mon état d’avancement
Si jamais un « sachant » (3 points au bingo réunion suivi de projet) passe par ici et veut me filer un coup de main en commentaires, je suis preneur
Bref, après tout ce blabla, attaquons donc l’intégration d’ORS au « stack » Elastic
On attaque avec un gros mot : « ELK »
Qu’est-ce que signifie donc « ELK » :
Elasticsearch
LogStash
Kibana
Il s’agit des 3 principaux composants nécessaires dans une majorité des cas quand on monte une suite Elasticsearch. Ah oui j’ai oublié de préciser : je ne suis pas un expert concernant Elastic. Pour tout dire, je découvre même Elastic avec ce side project. Donc j’espère que vous saurez être magnanime 😉
Elasticsearch est la base même de cette suite. Il s’agit d’un ensemble base de données + moteur de requêtes + API permettant d’y accéder. En comparaison avec d’autres bases de données, il a comme caractéristiques d’être facilement scalable en ajoutant des noeuds en fonction de vos besoins de redondance et/ou de performance, et de permettre de stocker des données non déterminées à l’avance. Oubliez les types précis associés aux colonnes des moteurs SQL habituels. Ici du moment que vous envoyez du JSON, il saura quoi en faire 🙂
LogStash est en approximation un ETL. Vous allez lui fournir des fichiers de logs et le mapping qui va bien, et il va en extraire les données qui vous intéresse, avant de les envoyer à Elasticsearch. Cette explication est plus « pour information » car dans le cas qui nous intéresse, ORS va se charger lui-même d’envoyer les données en base de données. Mais bon, on sait jamais… 🙂
Kibana enfin va vous permettre d’effectuer des requêtes en KQL sur la base de données, et de créer de jolies visualisations de toutes ces données, afin de les expliciter
Vous avez peut-être entendu parler de fuites de données récentes où les pirates se sont simplement servis sur des Elasticsearch exposés sur Internet et avec les logins/mots de passe par défaut. Et bien vous savez quoi, ça me surprend pas … J’ai trouvé que la partie modification des mots de passe par défaut était pas forcément explicité. Du coup, pour sécuriser un peu le bazar : https://www.elastic.co/guide/en/elasticsearch/reference/7.11/setup-passwords.html A faire idéalement dès que vous aurez fini l’installation d’Elasticsearch, cela vous évitera d’avoir à reprendre vos fichiers de configuration après coup
Les options que j’ai modifié dans les fichiers de configuration d’Elasticsearch et Kibana. Pas exhaustif mais une base de départ. Et pour rappel, ce sont des fichiers au format yaml donc l’oeuvre du démon où le moindre espace d’indentation en trop invalidera l’ensemble du fichier. Donc faites très attention à vos modifications, et backup des fichiers d’origine avant de faire quoi que ce soit
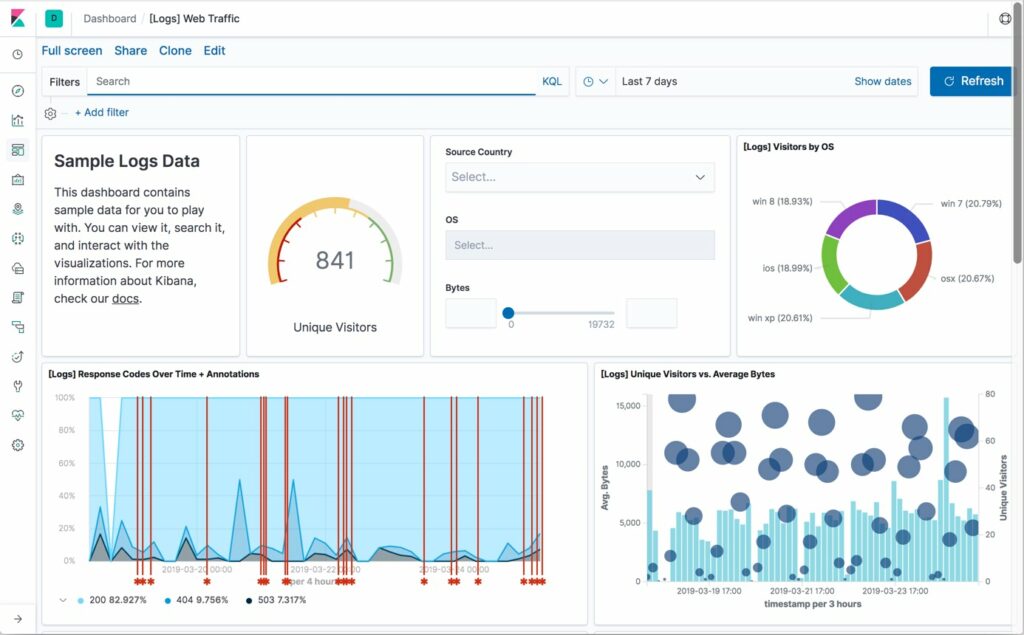
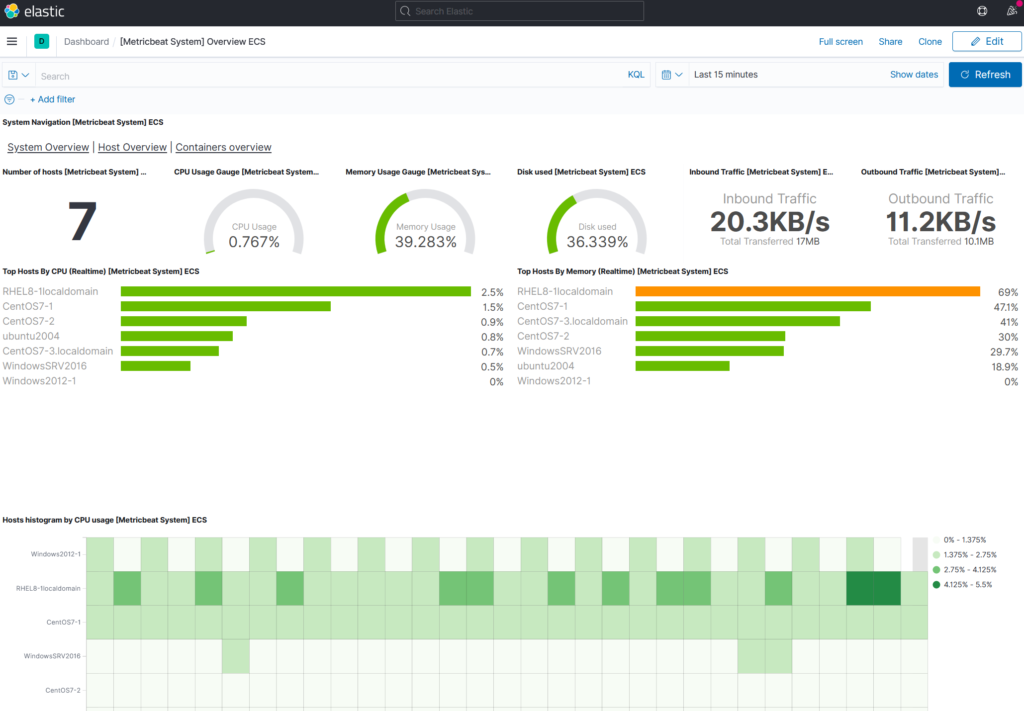
Enfin pour valider le bon fonctionnement d’ELK (EK même techniquement) avant de s’attaquer au paramétrage d’ORS, je vous conseille d’installer une des sources de données proposées par défaut dans Kibana dans l’onglet « Add data ». Me concernant j’ai installé MetricBeat qui permet de suivre l’activité de ses serveurs et s’installe très simplement
Oui, je n’ai aucune originalité dans le choix de mes noms de serveurs 🙂
Et si on faisait quelque chose d’utile maintenant ?
Maintenant que notre suite Elastic est installé, on va pouvoir paramétrer ORS pour qu’il s’interface avec celle-ci. Mais pourquoi faire déjà ? De base, ORS propose 3 fonctions de suivi de son activité qui peuvent ensuite être reportés dans Elastic :
Session reporting : ORS va stocker des informations sur chaque session créée. Le numéro appelant, la stratégie utilisée, heure de début et de fin,… Apparemment, on peut customiser ces informations en modifiant sa stratégie Composer 🙂
Performance reporting : ORS dispose d’une fonction de suivi de ses « constantes vitales », qu’il peut de base afficher dans les logs, et créer des alarmes Genesys associées en fonction de seuils. L’intégration à Elasticsearch permet de les monitorer pour suivre l’état de santé de ses nœuds ORS.
Node reporting : Ici ORS fournira des informations sur les différents nœuds actifs, ainsi que le host sur lequel ils tournent, ainsi que ses ports d’écoute TCP principaux
Activer ces 3 fonctionnalités se fait au niveau du paramétrage d’ORS (ou de la transaction list qui contient ses paramètres, cf. mon article sur l’installation d’ORS) dans la section elasticsearch
ors-es-session-report = true
ors-es-perfsnapshot-report = true
ors-es-node-info-report = true
ors-es-nodes = http://AdresseIPdeMonServeur:9200
username = elastic
password = changeme
Les 3 premières options permettent d’activer les 3 fonctions de suivi présentées précédemment, et les 3 suivantes de vous connecter à votre Elasticsearch. Le username et le password présentés sont ceux par défaut, avant modification
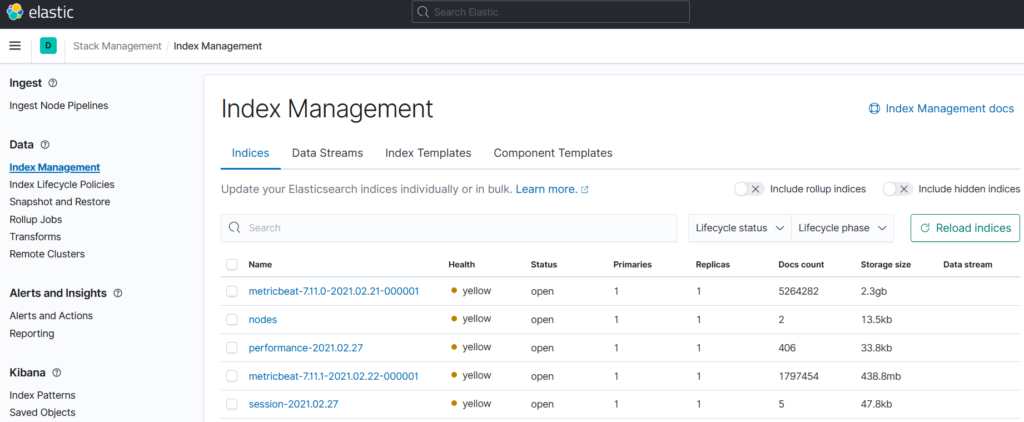
Une fois ces options paramétrées, redémarrez votre ORS et vous devriez voir des données remonter dans Kibana. Pour cela, connectez-vous à celui-ci et allez dans Stack Management > Index Management et vous trouverez de nouveaux « Indices » (l’équivalent d’une base de données dans Elasticsearch) nommés nodes, performance-YYYY.MM.DD et session-YYYY.MM.DD, chacun correspondant encore une fois aux 3 fonctions de reporting proposées.
Ingestion des données
Récapitulons : on a un Elasticsearch fonctionnel, un ORS configuré et des données qui remonte dans Elasticsearch. Maintenant, il pourrait être pratique d’effectuer des requêtes sur celles-ci.
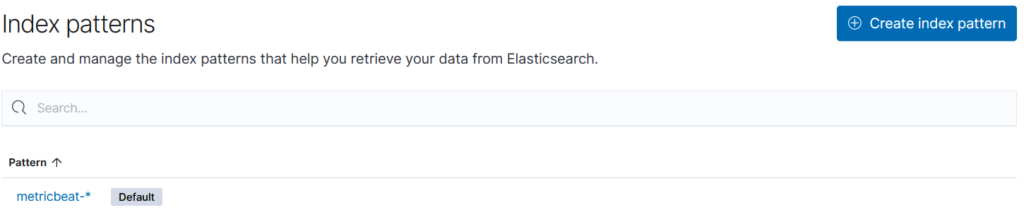
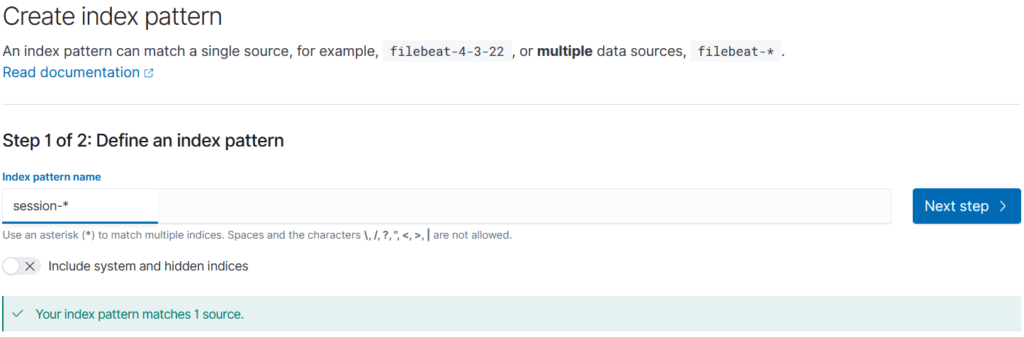
Pour cela, nous allons rester sur la page « Stack Management » mais aller désormais dans Kibana\Index Patterns, puis « Create index pattern »
Sur la seconde page, on va indiquer les index que l’on souhaite « regrouper ». En effet par exemple, les index de session vont être suffixés par la date du jour. Mais bien sûr, on veut pouvoir consolider les données de plusieurs périodes sur un seul graphique. C’est pourquoi par exemple pour consolider les informations de sessions, on va indiquer dans Index pattern name « session-*
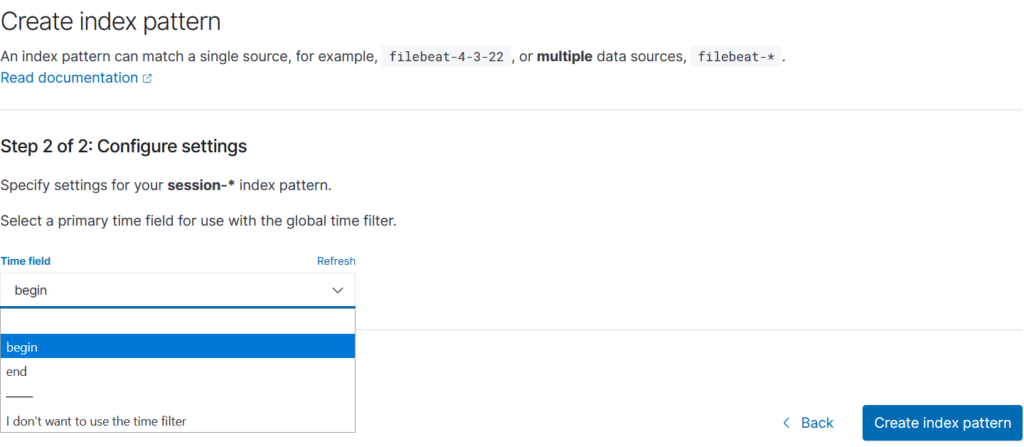
L’étape suivante va consister à indiquer s’il s’agit de données basées sur des informations de date, et auquel cas quelle donnée nous servira « d’abscisse ». Dans le cas des informations de session, on peut ainsi par exemple sélectionner la date de début de session, ou celle de fin :
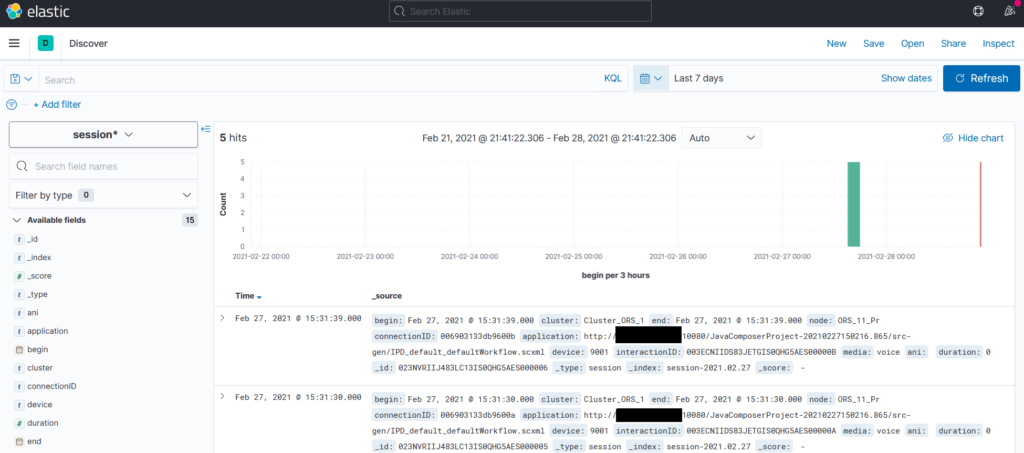
Maintenant que l’index pattern est créé, on va pouvoir requêter les données présentes dans Elastic grâce à la page Analytics > Discover puis en sélectionnant l’index pattern qui nous intéresse
Visualisation des données
Voilà, comme annoncé au début de cet article, ce n’est pas encore fini. Il me reste maintenant à faire de beaux graphiques avec tout cela…
Qui ne s’est jamais posé cette question ? Reste-t-il des licences pour continuer à déployer ou non. Et bien sûr, les outils Genesys sont là pour nous aider </ironie>
Cette méthode marche également…
Pour répondre à cette question pourtant simple, une petite astuce que je n’ai découvert qu’hier, du moins en version Linux. Et pour savoir où nous en sommes en termes de licences, nous allons aller voir notre ami FlexLM avec une commande toute simple :
cd /MON_REPERTOIRE_FLEXLM
./lmstat -c MON_FICHIER_DE_LICENCE.dat -a > recap.txt
Rien de très sorcier dans cette ligne de commande. Derrière l’option « -c » vous devez donc préciser l’emplacement de votre fichier de licence et « -a » est un alias pour « all ». Comme vous pouvez le constater, j’ai ensuite redirigé sa sortie vers un fichier texte afin de pouvoir l’analyser simplement. Exemple ci-dessous pour mon HomeLab :
lmstat - Copyright (c) 1989-2015 Flexera Software LLC. All Rights Reserved.
Flexible License Manager status on Sat 5/23/2020 11:28
License server status: 7260@CentOS7-1
License file(s) on CentOS7-1: /opt/genesys/FlexLM_1113/licence.dat:
CentOS7-1: license server UP (MASTER) v11.13.1
Vendor daemon status (on CentOS7-1):
genesys.d: UP v11.13.1
Feature usage info:
Users of 3GP82419ACAA: (Total of 156 licenses issued; Total of 0 licenses in use)
Users of 3GP21278ACAA: (Total of 156 licenses issued; Total of 0 licenses in use)
Users of 3GP21747ACAA: (Total of 156 licenses issued; Total of 0 licenses in use)
Users of 3GP08807ACAA: (Total of 156 licenses issued; Total of 0 licenses in use)
Users of 3GP09014ACAA: (Total of 156 licenses issued; Total of 0 licenses in use)
Users of 3GP09017ACAA: (Total of 156 licenses issued; Total of 0 licenses in use)
Users of 3GP08812ACAA: (Total of 156 licenses issued; Total of 0 licenses in use)
Users of 3GP21843ACAA: (Total of 156 licenses issued; Total of 0 licenses in use)
Users of 3GP20166ACAA: (Total of 156 licenses issued; Total of 0 licenses in use)
Users of 3GP21844ACAA: (Total of 156 licenses issued; Total of 0 licenses in use)
Users of 3GP20364ACAA: (Total of 156 licenses issued; Total of 0 licenses in use)
Users of ISDK_FACTORY: (Total of 999999 licenses issued; Total of 0 licenses in use)
Users of router_seats: (Total of 156 licenses issued; Total of 0 licenses in use)
Users of tserver_iscc: (Total of 999999 licenses issued; Total of 1 license in use)
"tserver_iscc" v8.0, vendor: genesys.d, expiry: 1-jan-00
floating license
SIP_Server_1 CentOS7-1 /dev/tty (v8.0) (CentOS7-1/7260 202), start Sat 5/23 11:26
Users of DESKTOP_SUPERVISOR: (Total of 15 licenses issued; Total of 0 licenses in use)
Users of tserver_tdn: (Total of 999999 licenses issued; Total of 0 licenses in use)
Users of ics_multi_media_agent_seat: (Total of 156 licenses issued; Total of 0 licenses in use)
Users of ics_custom_media_channel: (Total of 156 licenses issued; Total of 0 licenses in use)
Users of occ_preview: (Total of 156 licenses issued; Total of 0 licenses in use)
Users of cti_ha_option: (Total of 999999 licenses issued; Total of 1 license in use)
"cti_ha_option" v8.0, vendor: genesys.d, expiry: 1-jan-00
floating license
SIP_Server_1 CentOS7-1 /dev/tty (v8.0) (CentOS7-1/7260 302), start Sat 5/23 11:26
Users of tserver_sdn: (Total of 312 licenses issued; Total of 312 licenses in use)
"tserver_sdn" v8.0, vendor: genesys.d, expiry: 1-jan-00
floating license
SIP_Server_1 CentOS7-1 /dev/tty (v8.0) (CentOS7-1/7260 105), start Sat 5/23 11:27, 312 licenses
Users of CLDistributed: (Total of 999999 licenses issued; Total of 0 licenses in use)
Users of ha_redundancy: (Total of 999999 licenses issued; Total of 0 licenses in use)
Users of lds: (Total of 999999 licenses issued; Total of 0 licenses in use)
Users of MLDistributed: (Total of 999999 licenses issued; Total of 0 licenses in use)
Users of router_ha_option: (Total of 999999 licenses issued; Total of 0 licenses in use)
Reste à l’interpréter. La question que je rencontre la plus fréquemment étant « On peut encore ajouter du monde ? », nous allons regarder plus précisément deux lignes :
Users of tserver_sdn: (Total of 312 licenses issued; Total of 312 licenses in use) –> on a ici le nombre de connexions de types TServer/SipServer que l’on peut avoir en simultané. Commencez par le comparer au nombre de DN de type extensions dont vous disposez. Si vous en créez plus que ce nombre, ceux-ci ne seront de toute façon pas utilisables car le serveur refusera de les enregistrer N.B. : on est ici sur une infrastructure assez simple. Si vous aviez plusieurs SIPServer et/ou TServer, la répartition entre ceux-ci serait indiquée
Users of router_seats: (Total of 156 licenses issued; Total of 0 licenses in use) –> là ça sera le nombre de places occupées que vous pourrez avoir simultanément. La différence ? Rien ne vous empêche par exemple d’avoir dans le cas présent 200 places déclarées dans Genesys, dont 156 permettant la connexion au canal voix (les 312 licences tserver_sdn ci-dessus, divisées par deux car je suis en HA) et 44 places permettant de se connecter à un autre media tel que le chat. Par contre attention, quelque soit le mix entre « places voix » et « places chat », le total ne pourra pas dépasser les 156 router_seats indiqués
Voilà un petit article rapide mais que je serai sûrement amené à faire évoluer en fonction de mes pérégrinations licencesques ^^
Mise à jour du 31/03/2020 : Pardonnez moi cher lecteurs car j’ai pêché. En effet, et contrairement à mes habitudes, j’ai écrit cet article en me basant sur mes notes et sur mes souvenirs, ce qui fait que certaines parties étaient trop rapides ou absentes. D’où cette mise à jour. Décidément, Cassandra est bien compliqué à comprendre 😉
Sur les applications les plus récentes de Genesys, on note de plus en plus l’utilisation de solutions « libres ». Je veux parler par exemple d’applications telles que les bases de données Cassandra, les serveurs web Apache ou Tomcat, Kafka,… Problème, ces solutions, telles qu’elles, ne sont pas intégrées aux outils de supervision de Genesys que sont SCI, GA ou GAX. Or si elles plantent, votre solution sera tout aussi inutilisable que si c’était un composant Genesys qui se vautrait… Nous allons donc remédier à cela, en prenant pour exemple cette bonne vieille Cassandra !
Oui faire du NoSQL, ça peut rendre ronchon !
Le modèle, c’est important
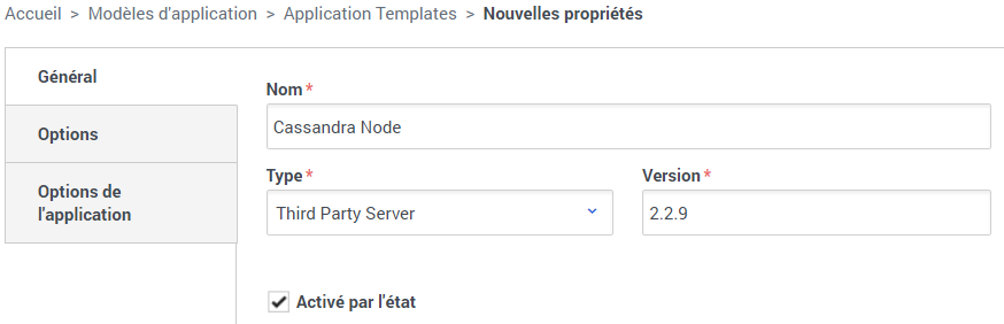
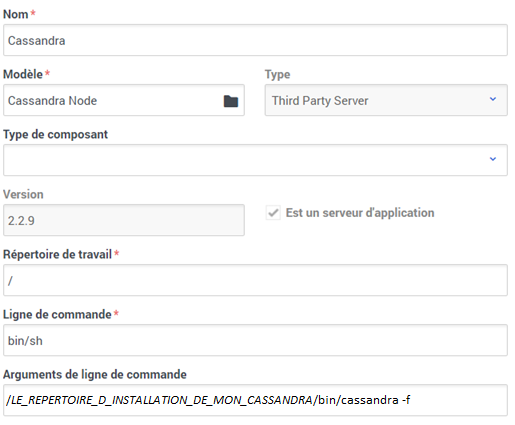
Tout d’abord, il faut savoir que Genesys propose de créer des modèles d’application pour ces serveurs tierces parties, alias comme le disent nos amis d’outre manche « Third Party Server« . Rien de spécial dans la création de ce template, je vais donc me limiter à une capture d’écran.
Oui, je déborde d’imagination pour mes noms de templates…
Maintenant que le template est créé, nous pouvons attaquer la création de l’application elle-même. Bien sûr celle-ci sera basée sur ce nouveau template « Cassandra Node ».
C’est toujours up ?
Pour vérifier que notre composant est toujours bien en mémoire, nous allons devoir nous assurer que le LCA de la machine hôte retrouve bien dans les process ce composant qui nous intéresse. Ici plusieurs écoles existent sous Linux, voici la mienne :
Répertoire de travail : « / » (oui, simplement /)
Ligne de commande : « bin/sh » (à adapter bien sûr si vous utilisez un autre shell). Celui-ci sera donc combiné avec notre répertoire de travail pour faire un bon vieux « /bin/sh »
Arguments de ligne de commande : ici on arrive dans la partie intéressante où on va spécifier le chemin vers nos exécutables. Cela dépendra forcément de votre installation mais vous devriez arriver à quelque chose du genre : « /LE_REPERTOIRE_D_INSTALLATION_DE_MON_CASSANDRA/bin/cassandra -f »
Avec ces options, vous devriez… pas pouvoir faire grand chose ! En effet, quand vous lancez cassandra en ligne de commande avec cette commande, il s’agit en fait d’un script qui s’exécute et qui va lancer la ligne de commande java « qui va bien » avant de disparaître tout en lui redonnant son PID. Nous allons donc modifier le script « cassandra » de lancement afin qu’il ne disparaisse pas. Pour cela, éditez ce script et remplacez dedans :
# The cassandra-foreground option will tell CassandraDaemon not
# to close stdout/stderr, but it's up to us not to background.
if [ "x$foreground" != "x" ]; then
cassandra_parms="$cassandra_parms -Dcassandra-foreground=yes"
if [ "x$JVM_ON_OUT_OF_MEMORY_ERROR_OPT" != "x" ]; then
exec $NUMACTL "$JAVA" $JVM_OPTS "$JVM_ON_OUT_OF_MEMORY_ERROR_OPT" $cassandra_parms -cp "$CLASSPATH" $props "$class"
else
exec $NUMACTL "$JAVA" $JVM_OPTS $cassandra_parms -cp "$CLASSPATH" $props "$class"
fi
# Startup CassandraDaemon, background it, and write the pid.
else
if [ "x$JVM_ON_OUT_OF_MEMORY_ERROR_OPT" != "x" ]; then
exec $NUMACTL "$JAVA" $JVM_OPTS "$JVM_ON_OUT_OF_MEMORY_ERROR_OPT" $cassandra_parms -cp "$CLASSPATH" $props "$class" <&- &
[ ! -z "$pidpath" ] && printf "%d" $! > "$pidpath"
true
else
exec $NUMACTL "$JAVA" $JVM_OPTS $cassandra_parms -cp "$CLASSPATH" $props "$class" <&- &
[ ! -z "$pidpath" ] && printf "%d" $! > "$pidpath"
true
fi
true
fi
par :
# The cassandra-foreground option will tell CassandraDaemon not
# to close stdout/stderr, but it's up to us not to background.
if [ "x$foreground" != "x" ]; then
cassandra_parms="$cassandra_parms -Dcassandra-foreground=yes"
$NUMACTL "$JAVA" $JVM_OPTS $cassandra_parms -cp "$CLASSPATH" $props "$class"
# Startup CassandraDaemon, background it, and write the pid.
else
$NUMACTL "$JAVA" $JVM_OPTS $cassandra_parms -cp "$CLASSPATH" $props "$class" <&- &
[ ! -z "$pidpath" ] && printf "%d" $! > "$pidpath"
true
fi
(Oui c’est barbare et je n’y comprends pas grand chose. Merci à mon collègue Antoine qui m’a filé cette astuce, un barbu par l’esprit, même sans la pilosité). L’idée générale est la suppression des commandes « exec » qui vont permettre de ne plus faire disparaître le script cassandra après qu’il ait lancé cassandra même.
Pour confirmer le bon fonctionnement de cette manipulation, allez faire un tour en ligne de commande sur votre hôte et faites un bon vieux « ps -aux | grep cassandra » (avec Cassandra actif). Ainsi vous devriez retrouver la ligne de commande que cherche LCA (en plus de la ligne commençant par « java »), et qui doit correspondre à la concaténation de « Répertoire de travail » + « Ligne de commande » + « Arguments de ligne de commande ». Si ce n’est pas le cas, faites les ajustements nécessaires.
Dans le doute, reboot !
Bon, maintenant on peut voir si l’état de notre application, et ça c’est bien. Mais pas moyen de l’allumer/éteindre via notre interface ! Rien de plus simple :
Un tour dans l’onglet « Options » de l’application (et non dans « Options de l’application »). OK en anglais c’est plus simple avec « Annex » et non « Options »…
Création d’une section nommée « start_stop »
Création des options start_command et stop_command Celles-ci devront correspondre aux commandes vous permettant de lancer et arrêter votre application
Sous Red Hat/CentOS 7, j’essaye de créer systématiquement un service pour gérer le process Cassandra. Ainsi ces fameuses options ont pour valeur « systemctl start cassandra » et « systemctl stop cassandra ». Attention, en fonction de l’utilisateur qui fait tourner votre process LCA, il sera peut-être nécessaire d’ajouter « sudo » avant, et de rajouter ce fameux utilisateur à la liste des sudoers (voir /etc/sudoers). Et vu que je suis dans un jour de bonté, un exemple de fichier .service servant de définition :
Avec tout ceci, vous devriez donc désormais pouvoir voir l’état de vos base de données Cassandra, contrôler leur arrêt/démarrage et même les ajouter à des solutions. Elle est pas belle la vie ? Et pour rappel, cette méthode générale est applicable à d’autres process Linux 🙂
PS : dans la mythologie, Cassandra a toujours raison, mais personne ne la comprend. En l’appliquant à ma propre relation avec cette base de données, je trouve le nom très bien choisi 😀
Bonus CentOS6 : Et oui forcément, une fois qu’on a une méthode pour un OS, il faut le faire sur un autre… Bref. Me voici sur une CentOS6 et pas de service à l’horizon. Du coup, j’ai remplacé la valeur de start_command par : – « /LE_REPERTOIRE_D_INSTALLATION_DE_MON_CASSANDRA/bin/cassandra -f « et celle de stop_command par : – « /LE_REPERTOIRE_D_INSTALLATION_DE_MON_CASSANDRA/bin/stop_cassandra » Votre esprit affuté remarque que « stop_cassandra » n’existe pas par défaut. C’est un mini script que j’ai placé à cet endroit et dont le contenu est le suivant :
ATTENTION : celui-ci va par contre couper TOUS les Cassandra tournant actuellement sur votre host et avec le user utilisé par LCA. Moche si vous avez des noeuds co-localisés… Si vous avez une solution, la zone commentaire sera ravie de l’accueillir 🙂
Et non, toujours pas de tuto SIP. Après tout, c’est mon blog alors je fais ce que je veux 🙂 Et surtout, je vais en profiter pour faire un petit tuto pour installer proprement ce composant pas forcément très original qu’est Genesys Administrator, mais qui propose ses petits pièges
Lire les pré-requis, toujours
Et oui, cela peut sembler tout bête, mais la plupart de mes soucis étaient dû à une lecture incomplète des pré-requis. Genesys Administrator nécessite Microsoft IIS, ça on est d’accord. D’ailleurs si celui-ci est absent, l’installation s’interrompt avec une erreur. Le problème est qu’elle peut très bien s’effectuer avec IIS mais sans les autres modules nécessaires. La conséquence ? Genesys Administrator ne sera pas déclaré dans IIS et même si vous le déclarez « à la main », pas forcément fonctionnel. Donc on coche bien les cases suivantes (cas d’une installation sous Windows Server 2012 R2) dans le Server Manager de Windows : Roles :
Application Server [.NET Framework 4.5, Web Server (IIS) Support,
Windows Process Activation Service Support (Select HTTP Activation]
File and storage Services [File Server]
Web Server (IIS) [Web Server [Common HTTP Features, Health and
Diagnostics, Performance, Security, Application Development [.NET
Extensibility 3.5, .NET Extensibility 4.5, ASP.NET 3.5, ASP.NET 4.5,
ISAPI Extensions, ISAPI Filters]], Management Tools [IIS6 Management
Compatibility]]
Features :
.NET Framework 3.5 Features [.NET Framework 3.5]
.NET Framework 4.5 Features [.NET Framework 4.5, ASP.NET 4.5, WCF
Services [HTTP Activation, TCP Port Sharing]]
Windows Process Activation Service [Process Model, Configuration APIs]
Après avoir installé l’ensemble de ces composants, l’installation ET la déclaration de Genesys Administrator devrait être OK. Mais on ne va pas en rester là…
Windows Server 2012, 2016, …
Et oui, GA n’est pas spécialement jeune. Et la doc va donc bien vous expliquer comment l’installer sous Windows Server 20003 & 2008. Mais au-delà, pas de son, pas d’images. Heureusement une autre documentation existe pour les versions 2012 et 2016 : https://docs.genesys.com/images/Repo/genadmin81dp.html Vous retrouverez ici les pré-requis nécessaires, mais aussi les modifications à effectuer sur le fichier web.config après installation pour que tout se déroule bien.
Y a shall not pass
Bon votre GA est bien installé, tout est bien qui finit bien ? Et bien… ça dépend. Vous vous connectez avec le compte « default » : tout passe comme sur des roulettes Vous vous connectez avec un autre compte Super Administrator :
C’est moche de se faire jeter de chez soi
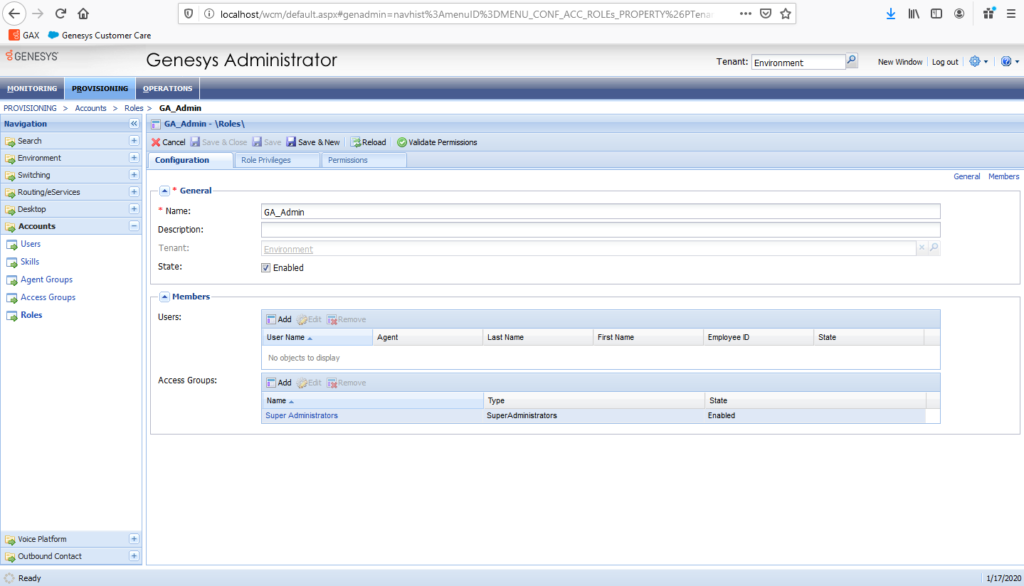
Dans les faits c’est assez simple. Pour accéder à GA, votre compte doit avoir les privilèges nécessaires, ou être le fameux « default ». Mais pour affecter ces privilèges, il faut accéder à GA… Donc si vous n’avez pas le compte default, vous êtes dans une belle boucle. Bien sûr, une solution existe. Vous pouvez désactiver temporairement cet accès via privilèges.
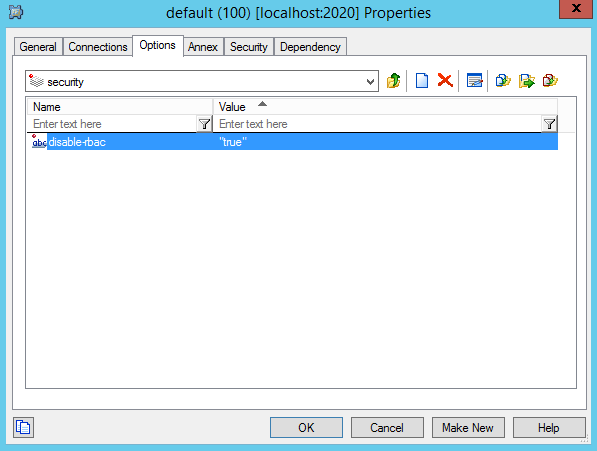
Pour cela,rendez vous dans l’application « default », créez une section « security » et l’option « disable-RBAC » à « true »
RBAC : Role Based Access Control
Une fois cette option créée, vous pourrez vous connecter avec n’importe quel compte sur GA. Et ainsi :
1) Création d’un rôle avec affectation à un groupe d’accès qui va bien
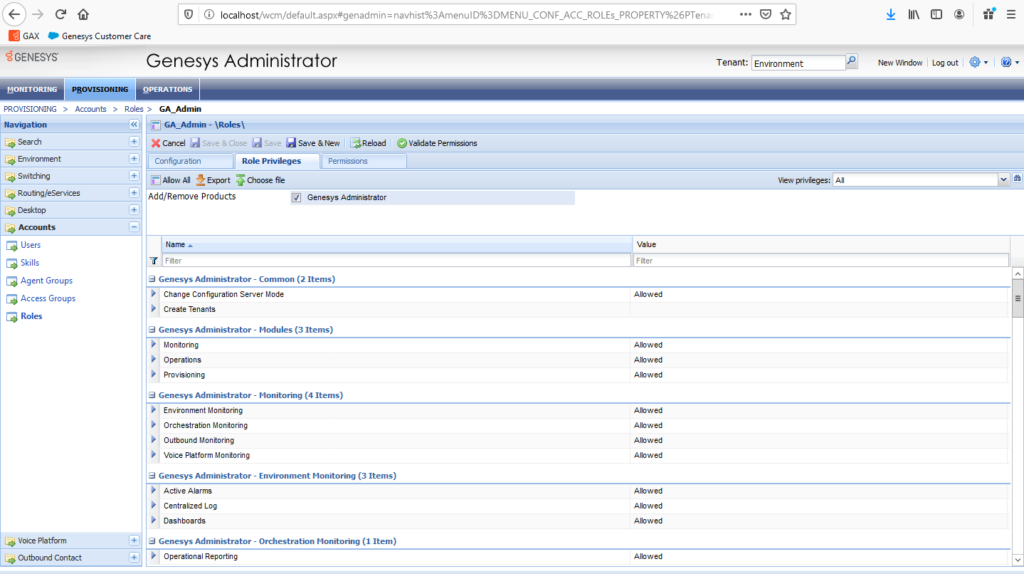
2) Ajout des privilèges nécessaires pour l’accès (si vous ne les voyez pas, pensez bien à cocher « Genesys Administrator » en haut)
3) Sauvegarde et modification du réglage [security]disable-rbac à false. Et oui, je pense que vous ne voulez pas laisser tout le monde entrer sur votre GA tout beau 🙂
One SCS to rule them all
Maintenant que vous pouvez accéder à Genesys Administrator, à vous les joies de la création de campagne d’appels ou de LRG avec des assistants 🙂 (Dis Mr Genesys, ça arrive quand dans GAX ?) Mais il vous manque peut-être quelquechose, la possibilité de voir l’état de vos applications et de les arrêter/démarrer. Si c’est le cas, pensez simplement à ajouter dans l’application « default » (toujours elle) une connexion vers votre SCS. Il vous suffira ensuite de vous connecter/déconnecter et tout ira bien 🙂
Voici pour ce tuto rapide, quand j’aurai le temps (plus de promesses) je rajouterai l’accès à la base de log, et la supervision de GA au sein de SCI/GA/GAX. De la supervisionception en gros 😉
Chacun sa nemesis. Ou ses nemesis. L’une des miennes est l’installation de Genesys Administrator eXtension (GAX pour les intimes). Malgré toute ma concentration et la lecture attentive de la documentation de Genesys, celle-ci me résiste encore et toujours. Ou plutôt me résistait !
5 minutes ? Chuis laaaaarge !
Et encore même en 5 minutes, j’exagère à peine.
Première étape, bien sûr télécharger l’IP de GAX qui convient à votre OS et votre envie de nouveauté. Pour cette étape désolé, mais je n’ai pas encore d’astuce pour l’accélérer 😉
Créez une base de données SQL de votre choix (MS SQL, Oracle ou Postgre), avec un user et mot de passe sélectionné avec soin, mais aucune initialisation de schéma
Assurez-vous que JRE 7 ou 8 est installé sur le serveur où sera installé GAX, ainsi que notre bon vieux LCA
Et maintenant la partie « magique », nous allons simplement créer un fichier texte qui contiendra les informations nécessaires au paramétrage de GAX. Appelons ce fichier setup.ini pour faire original 🙂
Configuration_Server_Host=IP_DE_LA_MACHINE_QUI_PORTE_LE_CONFIGSERVER
Configuration_Server_Port=PORT_DU_CONFIGSERVER
Default_Client_Application_Name=default
Configuration_Server_Username=COMPTE_ADMINISTRATEUR_GENESYS
Configuration_Server_Password=MON_MOT_DE_PASSE
Application_Object_Name=GAX (En fait le nom de l'application GAX que vous souhaitez avoir)
Database_Server_Type=oracle (ou mssql ou postgre en fonction de votre base de données)
Database_Host=IP_DE_LA_MACHINE_QUI_PORTE_LA_BASE_DE_DONNEES
Database_Port=PORT_DE_LA_BASE DE _DONNEES
Database_Name=NOM_DE_LA_BASE_DE_DONNEES_CREE_AU_POINT_1
Database_Username=COMPTE_DE_LA_BDD_CREE_AU_POINT_1
Database_Password=MON_MOT_DE_PASSE
Bien sûr les parties entre parenthèses sont à supprimer 😉
Pour finaliser l’installation, il ne vous reste plus qu’à taper la commande suivante dans le répertoire où GAX est installé :
java -jar gax.war -setup gax setup.ini
Et maintenant patientez quelques instants et votre GAX est installé !
Il ne vous reste plus qu’à vous connecter avec votre compte « default » afin de créer un rôle permettant la connexion à GAX, l’associer à un groupe d’accès « qui va bien » et enfin ajouter ce groupe d’accès à vos administrateurs utilisant GAX.
N.B. : précision de mon collègue Blackeyed : une fois le script lancé, celui-ci reste « bloqué » dans les faits, la configuration a été effectuée et il s’agit uniquement du process GAX qui vous attend gentiment. Vous pouvez donc soit l’utiliser tel quel (bof) ou le couper puis relancer proprement, a minima avec ce bon vieux ./run.sh & 😉
Maintenant vous attend le paramétrage fin de GAX, et là, c’est sûr que c’est bien plus de 5 minutes… 🙂
Allez c’est parti, une premier tutorial bel et bien consacré à Genesys. Mais je vous rassure, pour faire une installation sous Linux. Et celui-ci m’a bien cassé les pieds pour avoir quelque chose de propre…
Bref, c’est parti pour l’installation de FlexLM sous CentOS 7 !
Ouverture des ports
On commence par du simple et classique : ouvrir le port nécessaire à FlexLM. Je suis parti sur le classique 7260, mais ensuite à vous de voir selon votre installation.
Petite spécificité pour ce logiciel tierce partie sous Linux, il ne s’installe pas techniquement. C’est une simple archive à décompresser dans le répertoire que vous souhaitez. En faisant par exemple :
tar -xvf lmgr11.13-i686-linux-rhe4.tar -C /opt/genesys/FlexLM_1113
Souci, si vous essayez de lancer lmgrd immédiatement, vous aurez droit à un joli message d’erreur pour cause de dépendance manquante. Pour y remédier :
sudo yum install redhat-lsb
Suivi d’un :
sudo ln -s /lib/ld-linux.so.2 /lib/ld-lsb.so.3
Ayé, FlexLM démarre ! Enfin démarre, il est pas content sans son fichier de licence le petit gars. Allons donc le paramétrer 🙂
Paramétrer FlexLM
Première étape, on modifie son fichier de licence au niveau des deux premières lignes en remplaçant le nom du serveur (dans mon cas CentOS7-X, oui je manque d’imagination), ainsi que le chemin vers le démon genesys.d
SERVER CentOS7-2 001122334455 7260
DAEMON genesys.d /opt/genesys/FlexLM_1113
Maintenant que le fichier de licence est OK, la ligne de commande pour lancer FlexLM. Celle-ci se présente sous la forme :
Où -c indique le lieu où trouver le fichier de licence, et -l où le fichier de log va être écrit.
Je vous conseille de lancer cette commande à ce moment là pour vérifier que FlexLM se lance bien, et que tout est OK au niveau du fichier de log.
Si tout est bon, tuons à coup de kill ce bon vieux lmgrd pour faire un système de lancement propre, à base de service.
Création d’un service en systemd
CentOS7 a été l’occasion pour RedHat de passer de System V à systemd pour la gestion des services. Alias : jetez à la poubelle ce que vous connaissiez de /etc/rc.d & co… Bon je suis méchant, dans les faits, il y a de la rétro-compatibilité, mais essayons de faire avec une techno « récente » (2010)
Nous allons commencer par créer le fichier flexlm.service dans /etc/systemd/system
Ce fichier va indiquer à systemd comment lancer FlexLM, depuis quel répertoire, à quel moment lors du démarrage… Bref c’est hyper puissant, j’ai pas encore tout compris mais ce qu’il y a ci-dessous, ça fonctionne 🙂
[Unit]
Description=FlexLM
After=network.target network.service
[Service]
User=genesys
Group=genesys
Type=forking
WorkingDirectory=/opt/genesys/FlexLM_1113
ExecStart=/opt/genesys/FlexLM_1113/lmgrd -c licence.dat -l +/var/log/genesys/FlexLM/FlexLM.log
# Restart=on-failure
# Delay before service is stopped forcefully
TimeoutStopSec=5
[Install]
WantedBy=multi-user.target
Une fois le fichier créé, on va demander à systemd de recharger l’ensemble des fichiers .service disponibles, puis tester le démarrage de notre FlexLM.
systemctl daemon-reload
systemctl start flexlm.service
systemctl status flexlm.service
La dernière commande « status » vous permettra de voir si FlexLM s’est bien lancé, avec normalement une superbe ligne « Active: active (running) since Sat 2019-02-02 15:11:26 CET; 5s ago »
Etant donné que FlexLM est nécessaire à « quelques » composants Genesys, j’aime bien le mettre en démarrage automatique.
Pour cela, il ne vous reste plus qu’à taper
systemctl enable flexlm.service
Redémarrez votre serveur, et vérifiez au démarrage que FlexLM est bien présent.
Et maintenant c’est fini ? Non malheureux ! Maintenant, intégrons FlexLM à Genesys pour pouvoir le suivre et l’intégrer à nos solutions.
Monitoring de l’application
Vous avez déjà eu cette impression vous aussi ?
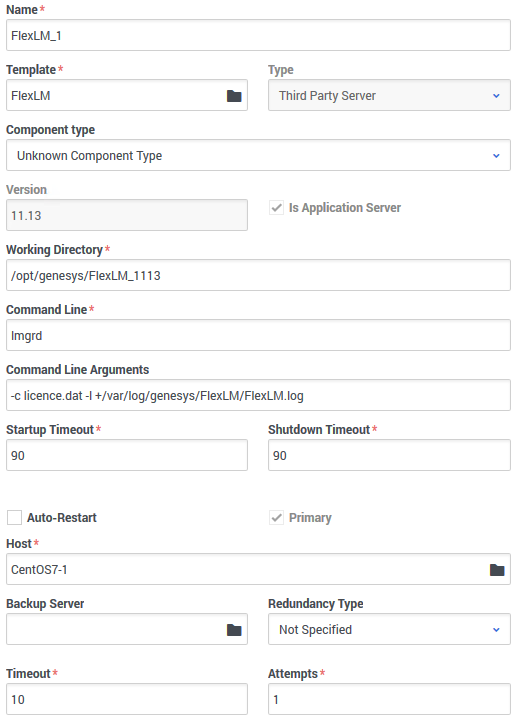
Tout d’abord de manière classique, nous allons créer un nouveau template d’application basé sur le modèle Third Party Server Dans l’onglet général, les options les plus importantes sont Working Directory, Command Line et Command Line Arguments. La concaténation de ces 3 options correspond à la chaîne de caractère qui sera recherchée par LCA pour déterminer si oui ou non FlexLM est lancé. Dans mon exemple, cela donne quelque chose qui ressemble à cela :
Rien de bien sorcier, faites juste attention à une concordance parfaite
A partir de ce moment là, vous devriez pouvoir voir le statut de FlexLM dans Genesys. Mais il reste encore une étape
Démarrage/arrêt depuis Genesys
En effet, si vous essayez de le démarrer-arrêter tel quel, le résultat n’est pas terrible. Ainsi, si vous arrêtez FlexLM depuis Genesys, systemctl « perd les pédales » et ne voit plus bien son statut. Alors autant faire les choses bien. Pour cela, nous allons créer des options dans l’annexe « start_stop ». start_command et stop_command vont remplacer l’usage habituel et nous allons y placer… les commandes systemctl précédemment créées 😉
On y est presque
Allez, une dernière étape. En effet, vous avez pu remarquer en tapant ces commandes dans un shell que celui-ci vous demande votre mot de passe. Pas pratique pour un appel non interactif.
C’est pourquoi nous allons modifier le fichier /etc/sudoers afin de lui indiquer que ces commandes SPÉCIFIQUEMENT ne requièrent pas de mots de passe. Pourquoi ce mot en majuscule ? Car on pourrait le faire pour l’ensemble des commandes. Mais comme c’est souvent, c’est plus simple, mais c’est pas propre niveau sécurité. Du coup, ajoutons gaiement dans ce fichier les 2 lignes suivantes :
Deuxième billet, et toujours pas du Genesys. Mais ça arrive. On reste dans les petits trucs et astuces sur RedHat 7.
Tu bluffes Martoni CentOS
Il dit qu’il voit pas le rapport…
Attention, cette manipulation est MAL ! Genre le support n’aime pas. Mais imaginons que vous souhaitiez installer GAX sur votre CentOS tout beau tout propre en 7.6. Et bien vous n’irez pas bien loin ! A peine le script d’installation lancé que vous aurez le droit à un superbe « OS version 7.6.1810 is not supported. » Diantre ! Que faire ? En production ? Et bien il aurait mieux valu lire les listes de compatibilités avant. Pour un lab ?… Allons donc faire une copie du fichier /etc/redhat-release par précaution.
Celui-ci contient la chaîne de caractère suivante :
CentOS Linux release 7.6.1810 (Core)
Modifions cette chaîne de caractère en :
CentOS Linux release 7.5 (Core)
Et hop ! L’installation se passe désormais sans soucis 🙂
Installation de quelques pré-requis Genesys
Le début d’une installation classique
Toujours dans la série « installons moultes composants sous Linux ». Et bien pour commencer, on va installer un joli petit paquet de dépendances nécessaires
Tout d’abord, deux packages nécessaires pour les installeurs Genesys qui sont toujours en 32 bits..
yum install glibc.i686
yum install libstdc++.i686
Ensuite installons le JRE Java, celui-ci sera nécessaire par exemple pour le GAX, ou pour certains composants nécessaires à GIR :
yum install jre
D’ailleurs, en passant, si vous cherchez l’emplacement où se trouve la JRE JAVA :
alternatives --config java
Cette commande vous indiquera les différentes versions installées, où celles-ci le sont, et vous permettra même de sélectionner celle active.
Maintenant PostgreSQL. Si vous souhaitez vous connecter depuis une machine Linux ne portant pas une base PostgreSQL à une de ces bases, il vous suffit d’installer la libraire suivante :
sudo yum install postgresql-libs
Et de manière plus générale, quand un message d’erreur vous indique qu’il vous manque un paquet ou une librairie, vous pouvez utiliser :
sudo yum whatprovides NOM _DU_TRUC_QUI_MANQUE
Cette commande vous indiquera en retour quel paquet installer grâce à yum install 🙂
Ajouter un utilisateur en tant que sudoer
C’est qui le patron ?
Et oui, tout faire en root, c’est mâââââââl. Mais passer d’un utilisateur normal à root et inversement, au bout d’un moment c’est casse-pied. Pour éviter cela, vous pouvez déclarer votre utilisateur comme sudoer. Ainsi il pourra exécuter les commandes nécessitant d’être normalement root, en les préfixant d’un simple « sudo ».
Mais trève de blabla, comment rendre une personne sudoer ? Imaginons que nous souhaitions rendre l’utilisateur « genesys_user » sudoer. Commençons par passer root puis éditons le fichier sudoers :
nano /etc/sudoers
A la fin de ce fichier, sous la ligne root ALL=(ALL) ALL, rajoutez la ligne :
genesys_user ALL=(ALL) ALL
Sauvegardez le fichier et déconnectez-vous du compte root. Mission accomplie !
Quoi de mieux pour commencer un nouveau blog dédié à Genesys que de parler de … Linux !
Ok je peux comprendre votre surprise. Mais de plus en plus de clients souhaitent basculer en partie leur infrastructure sur une base Unix, et quand on a pratiqué que du Windows depuis 15 ans, et que Linux évoque juste les cuites de l’IUT… Et bien ça pique. Donc dans cet article, et ceux qui le suivront, l’idée n’est pas de faire de vous un gourou barbu de Linux, mais au moins de connaître les bases nécessaires pour vos actions « de tous les jours ».
Etant donné les pré-requis Genesys, ces informations s’appliqueront à la distribution RedHat Enterprise Linux (RHEL) et son équivalent communautaire, CentOS. Et même, soyons fous, plus particulièrement à leurs versions 7.x, maintenant majoritairement supportées par les diverses solutions Genesys.
Maintenant, attaquons le vif du sujet !
Firewall, mon ami !
Vous ne passerez (presque) pas !
Et oui, commençons par laisser nos machines communiquer entre elles sur notre LAN.
Alors oui, je sais, une des solutions est de désactiver le firewall complètement. Mais déjà ça ne sera pas forcément autorisé dans l’environnement où vous travaillez, et ensuite laisser le pare-feu activé vous obligera à réfléchir aux ports que vous allez utiliser plutôt que de faire cela en mode « à l’arrache ».
Si malgré tout vous souhaitez le faire, ou pour tester si un problème vient bien du firewall :
systemctl stop firewalld
Attention, cette manipulation, tout comme le démarrage du firewall, demande d’être admin sur la machine sur laquelle vous travaillez.
Allez, arrêtons les bêtises et réactivons le firewall :
systemctl start firewalld
Pour vérifier que tout est revenu à la normale :
systemctl status firewalld
Cette commande devrait vous gratifier d’un joli : Active: active (running)
Petit aparté, « systemctl » est en fait la commande de gestion des services associé à Systemd, qui est le système utilisé par RHEL/CentOS 7. Mais nous aurons l’occasion d’en reparler.
Ajouter des ouvertures de ports proprement
Maintenant le vif du sujet, ouvrir un port. Imaginons que l’on souhaite ajouter un port, au hasard le 2020 😉 Pour cela une commande toute simple :
Deux commandes toutes simples, la première ajoute donc le port 2020, et ceci en tcp, quand la seconde recharge la configuration du pare-feu. A noter qu’il est aussi possible d’ouvrir une plage de ports (heureusement). Par exemple de 6000 à 6099 :
firewall-cmd --permanent --add-port=6000-6099/tcp
Rien de bien sorcier comme vous pouvez le voir.
Pour vérifier votre travail :
firewall-cmd --list-ports
Qui nous affiche fièrement : 2020/tcp 6000-6099/tcp
Et nous voici de nouveau avec uniquement le port 2020 tcp ouvert.
Forcer la mise à jour de l’heure système
C’est pourtant simple non ?
Ah les joies de lire les logs de plusieurs composants sur des serveurs différents, chacun décalés de quelques dizaines de secondes… Rien de plus pratique pour… s’arracher les cheveux. Première étape si ce n’est pas déjà fait, installer un démon ntp. Mais si après l’installation de celui-ci l’heure serveur est fortement décalée de l’heure réelle, alors le démon ntp va corriger l’heure système par petites touches. Vous n’avez pas envie d’attendre ?
ntpd -g
Ce petit « -g » indiquera de recaler l’offset entre les deux temps, en une seule fois et sans limite. Bien pratique ma foi 🙂
Voici pour ce premier « vrai » billet. Les notes pour le second dédié toujours aux astuces Linux est déjà commencé 😉